
Why Every AI Marketing Workflow Starts With a Second Brain (And What's Actually In It)


Last week I got on the phone with the Chief Human Resource Officer of a PE-backed healthcare technology company. Her teams had already burned through the company's entire annual Claude tokens budget, four months into the year. She was debating whether to keep paying for it. The teams weren't getting ROI. The outputs felt generic enough that nobody trusted them, which meant nobody used them, which meant the budget was on fire for no reason.
I asked how the teams had been trained, what shared context they'd been given, what common ground existed for the work.
Her answer, almost verbatim: "we're just kind of letting them figure it out on their own."
I was curious. I asked three questions: Do you have good documentation around what your business does, who you do it for, and why your way is better than the competitors? Do you have good documentation around the products you sell, who they're best for, how they work? Do you have good documentation around the selling process and where different workflows fit into it?
Her answer: Mostly no. Some of it lives in some heads. Some lives in a deck nobody opens. Some doesn't exist at all.
Then I told her something that changed her face. "Every employee using these models right now is making decisions with only the information available to everyone else on the planet using the same model. And unless they've turned web search on, they're working off training data that's a year or two old."
There was a pause. Then: "well, what does that mean?"
It's the context, silly
What it means is that the bottleneck almost nobody is solving for is context. And almost everyone thinks the bottleneck is something else.
The pattern I see almost weekly: a team buys Claude Pro or ChatGPT Plus, somebody builds a few skills or custom GPTs, the outputs come back generic, the team blames the tool, somebody declares "AI doesn't work for us," and they revert to the old workflow. Usually within six weeks.
That whole arc is misdiagnosed. The model didn't fail you. The context did. You asked a brilliant generalist to do work for a company it had never heard of, with products it didn't know existed, for an audience it had never met, in a voice it had never read. Of course the work came back generic. You handed it nothing.
The reframe to repeat to your team until it sticks: AI doesn't fail because of capability. It fails because of context. Prompting matters less than it did two years ago. The frontier models (Anthropic, OpenAI) and their harnesses are good enough that prompting is a small lever now. Context is the big one.

Why this realization landed for me
Anyone who's been using Claude Code or Claude.ai with Projects already knows this intuitively. A Project is a folder of information Claude reads from to help you better. That's the whole feature. It's not magic. It's a folder.
But two years ago, this wasn't obvious. The whole reason ChatGPT Projects took off was that people had a quiet little realization in late 2023: "oh my gosh, I can give the model memory and context that isn't available publicly, and it produces work that's better than if it didn't have it."
Most marketers learning AI today never went through that era. They got a Claude license in the last year, started prompting, and have been disappointed ever since. They skipped the formative moment, and the formative moment is the whole game.
The wrapper tax
Here's what's quietly true about most of the AI marketing tools that have busted onto the scene in the last 18 months: they are essentially context wrappers. They're forcing you to do the manual work of pulling your context together, and then charging you a SaaS fee for the GUI that made you do it. This isn't a knock– let me explain.
Claude Design. Why does Claude Design produce better visuals than asking Claude chat for the same thing? Not because the model is smarter inside the wrapper. Because Claude Design forces you to spend thirty minutes to three hours (depending on what you already have) defining how your brand should look, sound, and feel. Fonts, color palette, logo lockups, components, do's and don'ts. If you have those visual brand identity components stored in a way the LLM can understand, Claude chat will produce visuals that are as good or nearly as good as Claude Design. The difference is the GUI. Claude Design is selling you a context-input form.
AirOps. The AI marketing automation platform of the moment. (I did a whole review a few months ago, go read that for more thoughts on AirOps specifically.) But the core observation: AirOps is a wrapper that forces you to provide significant amounts of very granular context that the models need to run marketing automation flows. ICP definitions per ICP. Key brand statements per product per ICP. Visual identity, tone rules, competitor positioning. Initial setup is one to four weeks just to get all the information in. Marketing teams are notoriously bad at documentation and artifact keeping, which is why this takes so long. But once it's set up, AirOps produces better outputs than the same workflows in Claude Code or Codex, because AirOps forced you to provide it with the right context in a structured way the LLM can read.
Once you internalize this, it's the context, stupid, and how to provide it, you can use LLMs better in any workflow. With a $2,500-a-month AirOps license. Or with markdown files in a GitHub repo. Or with Claude Code on your laptop. Same brain. The wrapper is just the markup.
If you have a Second Brain, these wrapper tools become force multipliers and are worth every dollar. If you don't, you're paying a wrapper to fake a foundation for you. Cheaper to fix yourself, and a lot more durable.
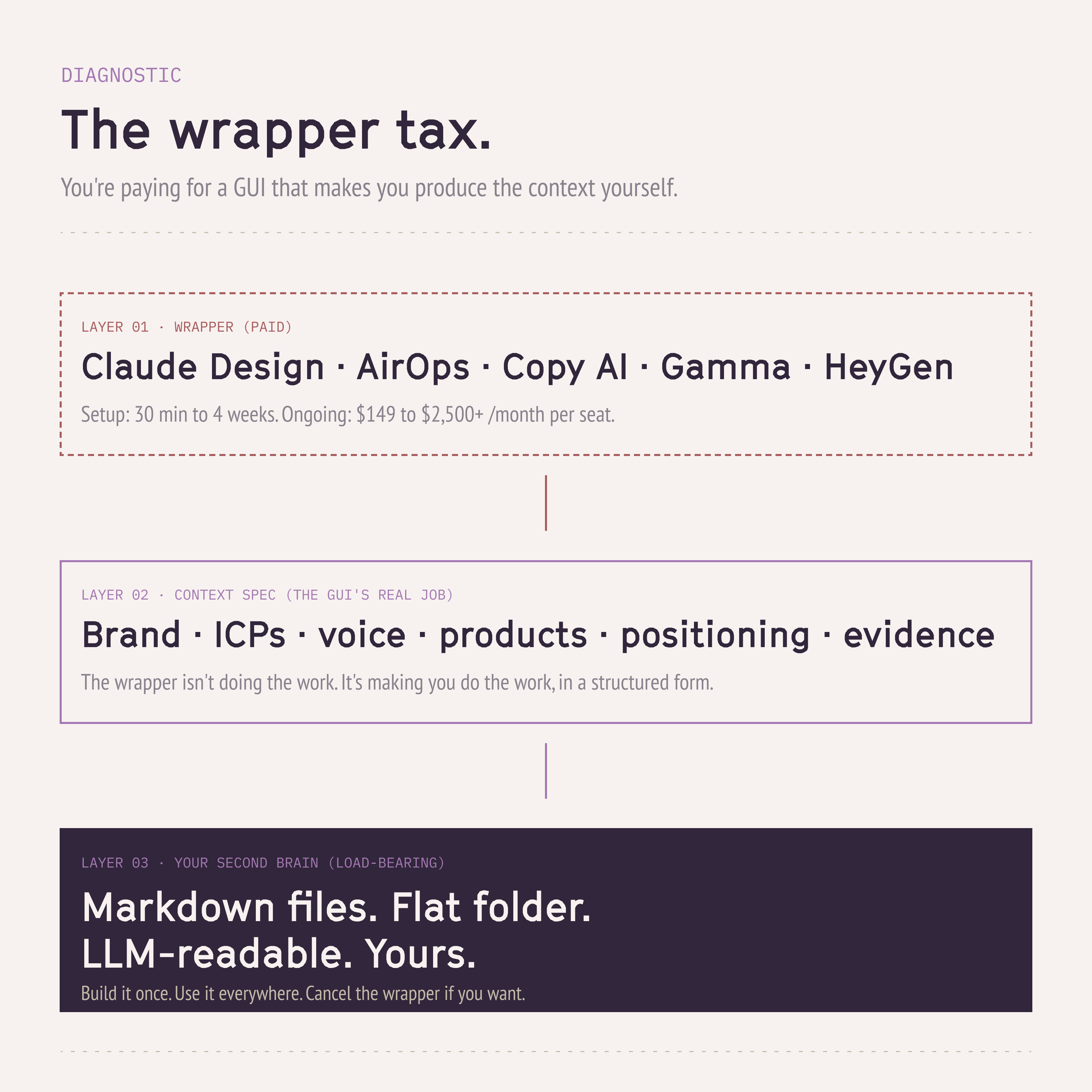
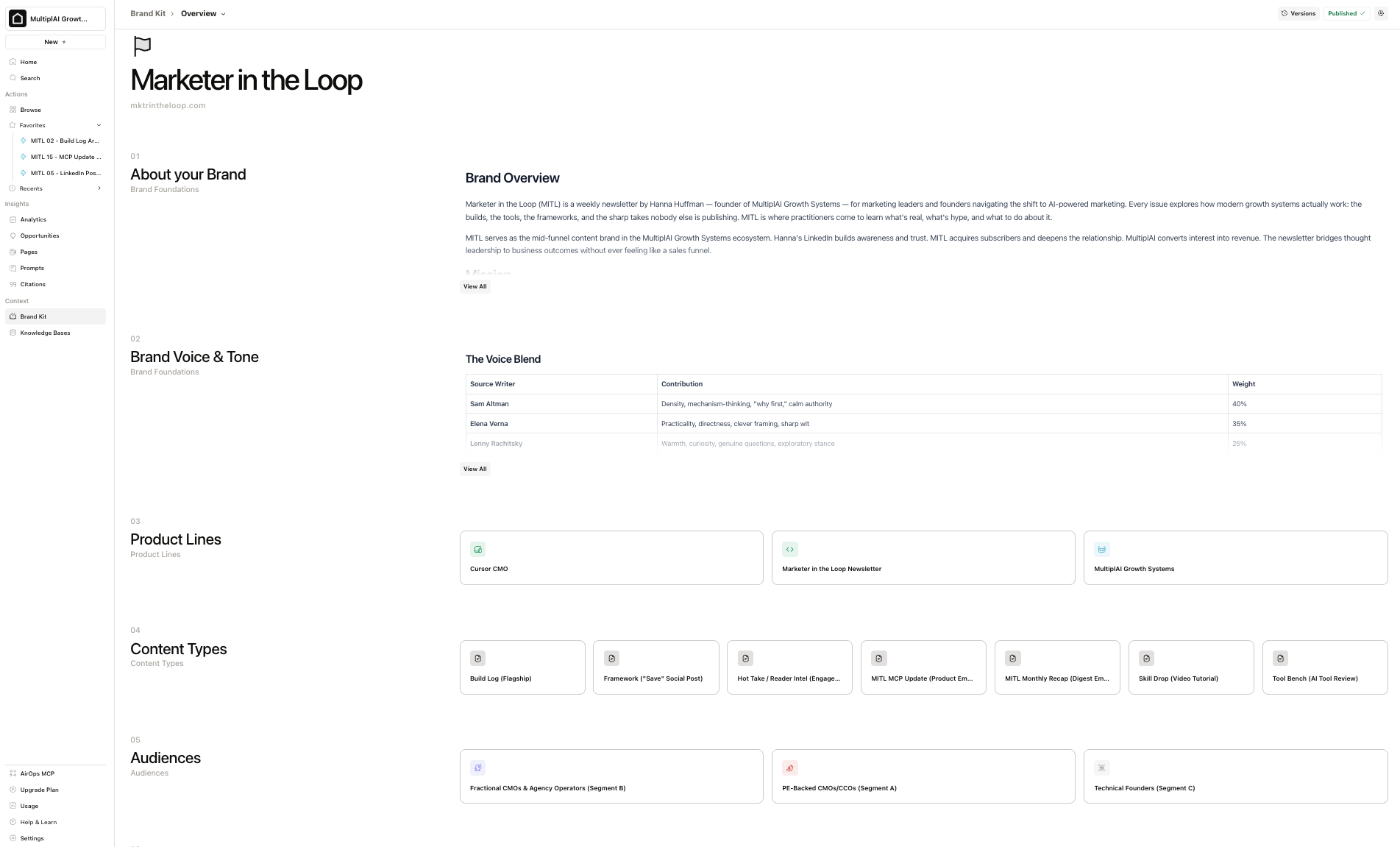
What a Second Brain actually is
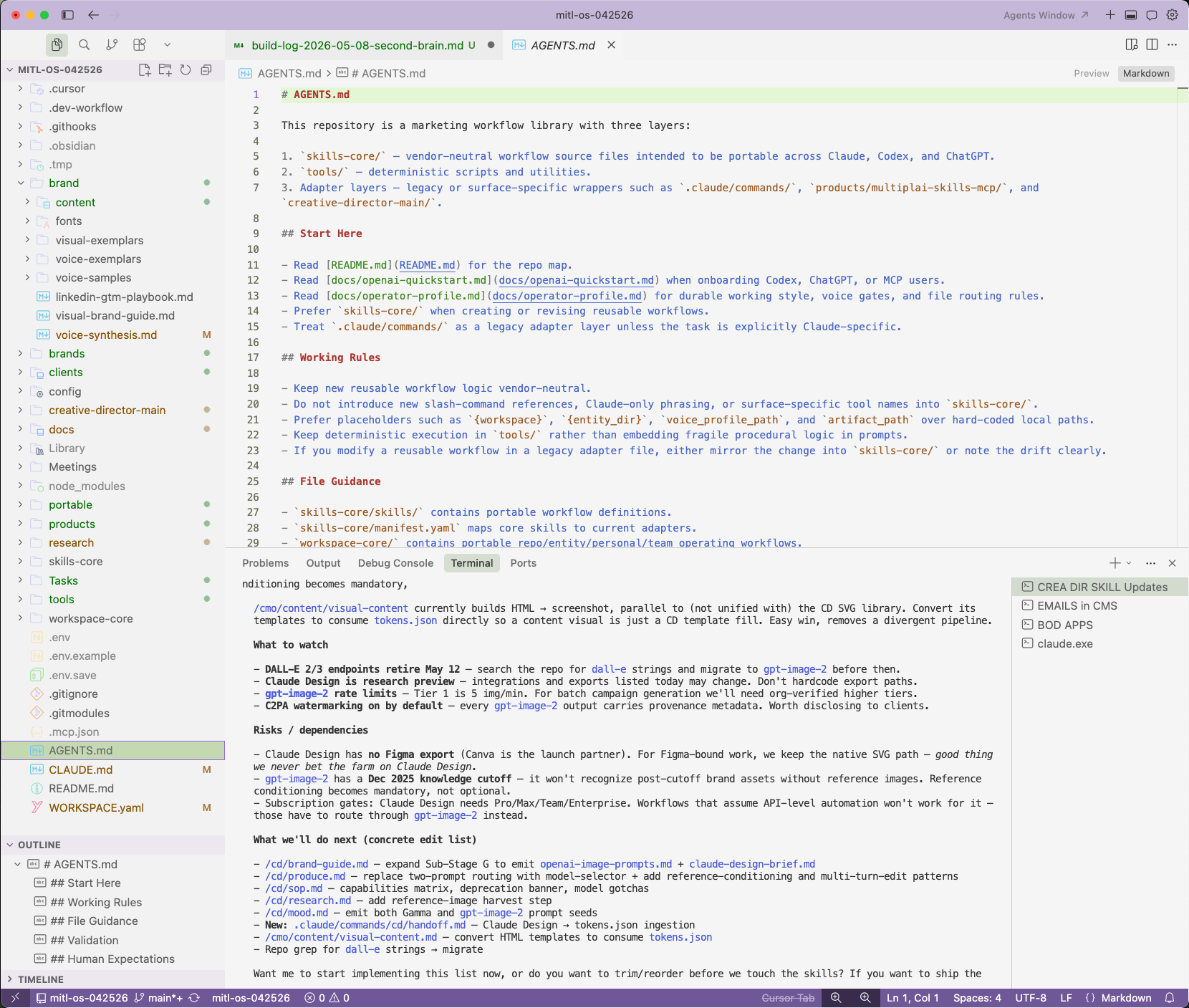
The simplest way to explain it: a Second Brain is an employee handbook expressed as a collection of simple markdown files, written for the AI employee doing the job you're asking it to do.
You've probably heard the new-employee analogy a hundred times by now, so I'm not pretending this is new. But it lands so cleanly that I keep using it.
Imagine the LLM is a new hire on your marketing team. They show up Monday to run social media. You could assume they know how to do this, and they could probably figure out the mechanics on their own. "how do I make a carousel post on LinkedIn?" They Google it. That's the kind of thing an LLM can learn without you teaching it.
What they cannot Google: your social media strategy. How many channels you run. Posting frequency. Your ICPs and how they think. Which product lines you pitch to which ICPs. How you talk about your products. What your products cost. Your posting calendar based on conferences and product releases. Your last six months of best-performing posts and what you learned from them.
You'd have to tell a human all of that. Same with the LLM.
Then the org-level move. For each marketing motion you run: what's the standard operating model, where does the documentation live today, what exists, what needs to be created? Once you start writing it down, you have a library for that job. Then the next question. How many libraries do I need? A social media manager library. An email marketing manager library. A CRO manager library. One per job the AI is doing.
Some artifacts are guides, principles, standards, strategy. Others are process-specific (when we produce a webinar, what's step one, step two, step three?). A great resource on this is the Profound marketing engineer certification. It talks about systems engineering and workflow mapping in exactly this way.
Where it actually lives
Three sub-decisions, in order: storage location, file format, access pattern.
Storage location. Common candidates are Confluence, Notion, Google Drive, GitHub, or local. Pick a central source of truth. Then organize it. Get your Marie Kondo on. By job type? By brand? By product? Lots of valid answers, and that's a whole rabbit hole I'll save for another day.
File format. Markdown is the answer. Flat, low-token, easiest for LLMs to read, keeps token costs down, improves accuracy. Avoid gigantic Excel workbooks with twelve tabs where only one matters and the headers are messy. It's a disaster. If a workbook is the right format for something numerical, make sure there's one tab, clean headers, clear labels, and prefer CSV. Word docs are fine if you keep them short. Every time the model consumes a context document, it spends tokens. Give the LLM the minimum amount of information it needs to do the job. No more, no less.
Access pattern. Notion and Confluence are great for corporate wikis. They are bad for continuous, scaled LLM consumption, because every workflow has to make an MCP or API call out to those environments and pull data back into the session. Latency, cost, and friction add up fast. GitHub or local storage gives the model flat access. It just reads the files. No round trip.
The pattern I've seen work in practice: keep the corporate wiki in Notion or Confluence (humans love it there, it has comments and search and permissions), but mirror your AI-native context environment in GitHub so AI workflows have flat, fast access. One is for humans. One is for models. They cross-reference and stay in sync.
The six things that go in it
This is the framework I walk through with every reader that purchases our Marketing Second Brain Install:
- Positioning. What you do, who you do it for, why your way is better than the competitors.
- Personas / ICPs. Who you sell to, what they care about, how they make decisions.
- Voice profiles. How you sound, what you sound like in the wild, anti-patterns, exemplars.
- Brand identity. Visual system: type, color, logo lockups, components, do's and don'ts.
- Product and offer info. Products, pricing, packaging, what fits which persona.
- Frameworks, customer evidence, and output exemplars. Anything that shapes the look, sound, and feel of what you produce.
What the install does, beyond the artifacts: it eliminates the decision fatigue of "what do I need to create, what's my folder structure, how many artifacts, what goes where." I give you a folder tree that works for most people in your shoes. We walk through MVP-state versions of the five or six things you need first. Initial install: about twenty minutes. Most people come back to keep iterating. More robust artifacts. More jobs. More personas. But after the twenty-minute install, you have a working Second Brain that's consumable by everyone on your team.

The tools that depend on it
Claude Skills. Arguably less useful than they've ever been right now, because the models are so capable now that they don't need to be told how to do a task. What they need is information on how you prefer to do that task, or how you typically do it, especially when the answer has to be consistent across the team. That's what Skills should be doing. Plus pointing the model at the proprietary information in your Second Brain it must use. If you're using Claude Skills right now and you don't have a Second Brain, I doubt those workflows are very useful to you if you actually looked in the mirror and were being honest with yourself.
Claude Design. Already covered above. Context wrapper. Needs your brand identity files, or it's a generic visual generator.
Content tools like Copy AI, AirOps, Gamma, Canva AI: same dependency. They all need the same foundation to produce anything that sounds like you instead of like the internet.
Video gen like HeyGen, Remotion, the new wave of tools shipping every month: same dependency.
Literally none of this downstream tooling produces anything valuable without the Second Brain. It's the first step to get your organization to a point where it's producing usable, valuable work with these tools.
Two paths forward
Path 1: DIY. You can absolutely build this yourself. There's nothing proprietary here. It's actually very simple once you get over the initial learning hump of "oh, I get it, it's just a folder structure, it's just markdown files," and you fully grok why you're doing it.
The real friction with DIY isn't the work. It's that the person who needs to build this is typically the busiest person in the entire organization. A CMO. A senior marketing leader. A founder pre-marketing-team trying to spin up initial distribution before hiring a team or an agency. That friction is exactly why the Foundation Install exists. It isn't a moat. It's a time saver.
Path 2: Foundation Install ($149). You download the initial folder structure (works for most people who look like you), walk through the workflow that helps you build the initial context files, then I put twenty minutes on with you on Google Meet to screen share, make sure you're set up, answer questions, and confirm you know how to use it going forward.
After the install, ongoing questions go through the newsletter. I reply to every email, I'm active on social, and I keep a small number of advisory slots open per quarter for people who want two to four sessions a month for ongoing support, build performance reviews, and org rollout strategy. Very limited capacity, but I do offer it.

What's coming next
This was the why. The diagnostic, the framework, the components, the storage decisions.
Next Friday (May 15): the where. Once you have the Second Brain, where does it actually live? GitHub vs. Notion vs. MCP vs. custom app. The decision frame, with tradeoffs.
May 22: the how. Agent vs. chat. When does a workload earn an agent (Cursor CMO, custom MCP server, scheduled jobs)? When is chat just fine?
May 29: the which model. Multi-model design. Claude vs. OpenAI vs. specialty models. Best model per job, plus outage and usage-cap resilience for when one of them goes down on a Tuesday morning.
By the end of the month, you'll have walked through the full operating system. You can build it yourself; or, we'll help you install one!
Premium subscribers can install their "Marketing Second Brain" in less than an hour by installing our MCP server– a complete AI-Marketing OS that runs on Codex, Claude, or any other LLM.


