Where Should Your Team's AI Workflows Actually Live?


I get this same question in my DMs about six times a week. It's coming from MITL Pro members, fractional CMOs, and a few in-house marketing leaders who've been quietly learning Claude Code on nights and weekends. They've shipped five or ten workflows that actually work, and they can see exactly where their team could be in six months. What's stopping them isn't the building part, though – it's everything around it: where the files go, how to hand a workflow off, how to actually train the team to use the thing. This leads to... them continuing to do the work themselves, the team never being "armed" with the new tools, and the compounding "AI efficiency flywheel" never starting.
The mirror version is just as common. In this scenario, the leader has not actually learned what their operators are building. The operators are asking how to share what they have made. The leader has no answer.
This week, I am summarizing what I know about the four real surfaces, the decision frame I use with paid clients, and the thing nobody is naming about why even Notion's design team prototypes outside of Notion.
Before you pick a surface, separate context (your second brain) from workflows (the SOPs that run on top)
When marketing leaders say "AI workflows" they usually mean one of two artifacts. The first is context: brand strategy, positioning, personas, key messages, product lines. The things the AI references so its output is on-brand and usable. Your marketing second brain (I wrote a separate piece on what's in one and how to build it). The second is the workflow itself: the instruction document that tells the agent how to do a job. Write the weekly ads report. Repurpose a webinar. Draft a LinkedIn post for product line X. SOPs for an agent. They sit on top of the second brain and reference it.
This piece is about the second one. Once you have the brain, the question is where the workflows that run on top of it should live so your team can actually use them.
These workflow files already have a name (Claude calls them skills, Codex calls them runbooks)
In Claude and Claude Code these are called skills. In OpenAI Codex they are called runbooks. Same thing under different vendor labels: a small YAML header that tells the agent when to use the skill, and a markdown body that walks it through the steps. An SOP for an employee who happens to be an LLM.
You probably have a few already without realizing it. The Slack message you keep reusing to brief Claude on the weekly report. The 800-word doc you wrote so a contractor could run your repurposing flow. The Notion page titled "How I do landing-page copy reviews." Those are skills. They are just not stored anywhere an agent can find them on its own.
The community is already at scale: VoltAgent's awesome-agent-skills repo has over a thousand shared skills, wshobson/agents ships 185 agents and 153 skills. Paid subscribers to this newsletter can access a whole "second brain" and 47 marketing skills that integrate with it using one 2 minute MCP install. The unit of leverage is a markdown file in a folder. That part is settled. The question is whose folder, on what surface.
The right question isn't which tool, it's which surface will actually execute the workflow
The conventional question is "which tool should we use." This is the wrong question. The right question is "where will the agent execute this, and who needs to be able to run it on a Tuesday morning?" Pick the surface that answers both, not the one that already holds your other documents.
I'm calling this the Execution Surface Rule™. Three surfaces, in the order I see them work in practice.

Notion and Confluence belong as the human-reference layer, not the AI execution layer
Teams reach for this first because it is where every other document already lives. Permissions, sharing, training, all sorted. Adding another folder costs nothing on Monday.
It is also the worst option for the AI execution layer, and the reasons are mechanical, not religious. The files are not flat markdown on the operator's filesystem. Every time the agent needs them, it has to call out through a connector (an API integration, or an MCP server if the platform offers one). Slow, token-heavy, sometimes outright blocked by IT. Notion's MCP server mitigates the speed problem but every team member has to install and authenticate it themselves; Confluence and SharePoint vary widely. Word docs, decks, and PDFs are slow for the agent to parse and cost more tokens than markdown for the same instructions.
These tools were designed for humans to read, not for agents to execute against. Keep them as the human-reference layer. Stop using them as the execution layer for AI workflows. This is the single most common mistake I see right now.
GitHub is the current default for good reason, and the change-management piece is what makes it work
Native markdown, native version control, fast for agents. Claude Code, Cursor, Codex, Copilot, and Gemini CLI all integrate directly. Open the repo, agent reads the file, done.
What matters more than the storage is change management. When an operator uses a skill and notices something is off, they can open a pull request directly from inside Claude Code or Cursor. You review. You merge or branch. This is the missing affordance in every Notion-based system: structured human review of changes to shared workflows. Without it, every well-meaning edit becomes a fork and the team's "shared system" is actually six private copies that drifted last quarter.
The newer piece worth knowing: GitHub launched gh skill on April 16, 2026, a CLI package manager for agent skills that works across all the major coding agents and writes to .agents/skills/ or .claude/skills/ automatically. GitHub is now the formal distribution layer the way npm is for JavaScript packages. If you have at least one builder on the team, this is what I usually recommend.
MCP server is where I have moved most of my distribution, and where consultants should start
Quick definition, because I get this question every week: an MCP server is like a USB port for AI. Companies (and individuals) set up MCP servers so AI tools can plug in and use their software without ever seeing the underlying code. Notion has one. So do Stripe, Cloudflare, Salesforce, Auth0, New Relic. As of March 2026 there are over 10,000 public MCP servers, 97 million monthly SDK downloads. OpenAI adopted MCP in March 2025, Google in April, Microsoft Copilot Studio in July. One-year-old protocol, integration layer already won.
Why I moved most of my distribution here:
- The team does not see the code base. One MCP connector install (three minutes) and the workflows are available inside their agent. That is the whole onboarding.
- Protects your IP. If you are a fractional CMO, agency owner, or consultant and you want a client team to use your workflows without giving them your full system, this is the right answer.
- Cleaner permissions. No "they accidentally pushed to main" stories.
- Trade-off: harder to set up than a GitHub repo. Build the server, host it (Cloudflare is the standard), maintain it. Good news is your agent does most of the work; I built the MITL MCP server in Claude Code, then moved to Codex for the Cloudflare browser steps.
MITL Pro members install one MCP connector and get every skill I have built. Three suites, twenty-eight skills as of this week. They never see GitHub. They run /long-form-writing or /weekly-ads-report and the workflow executes. That is what Surface 3 looks like in practice.
A custom app on top of a repo is the fourth surface, and adoption is uneven... even at Notion
Two months ago, I watched Brian Lovin (who runs design at Notion) walk through their internal "prototype playground" on Claire Vo's How I AI. It is the cleanest articulation I have seen yet of what the fourth surface actually is, so it is worth putting on the table even though it is mostly premature for the teams reading this piece.
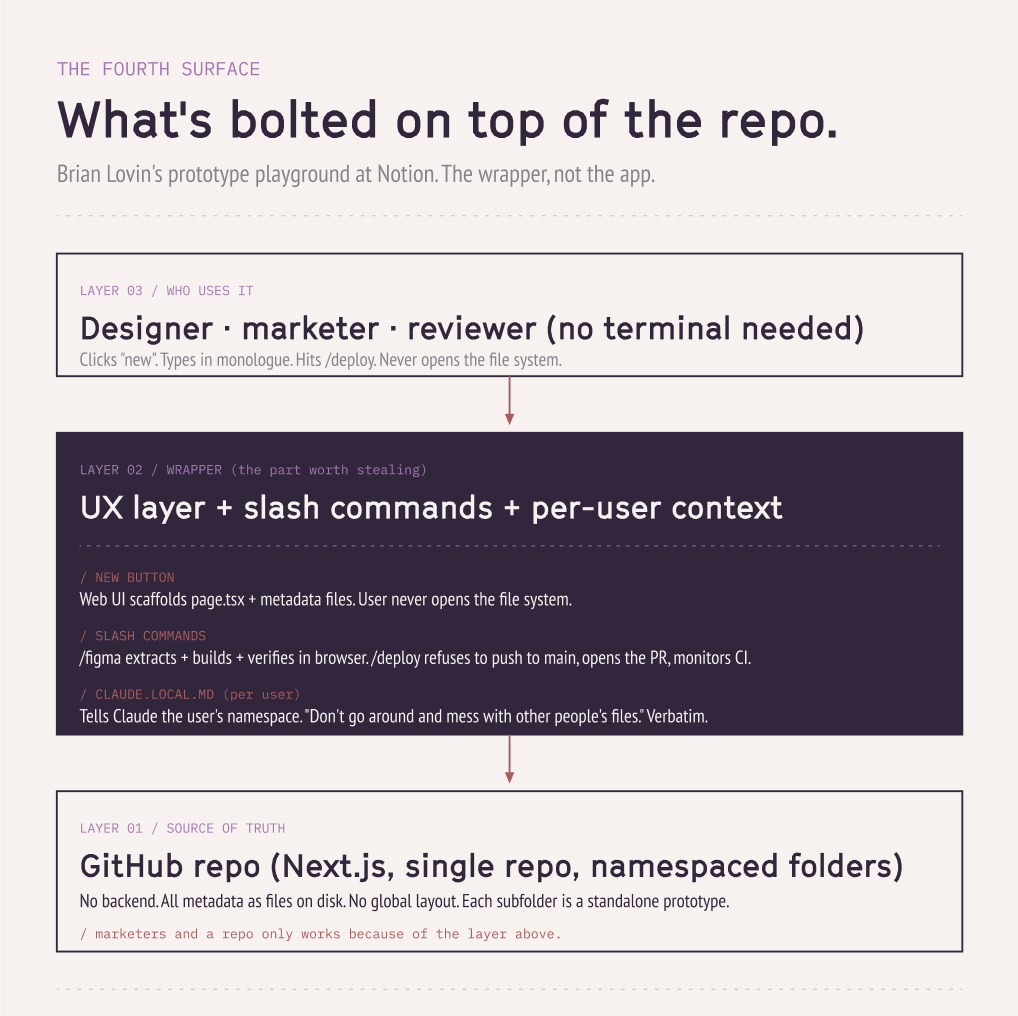
Prototype playground is a Next.js app on Vercel. A single repo. Every designer (and any PM or engineer who opts in) gets a namespaced folder. There's no backend. All metadata as files on disk. The transferable lesson is not the React app. It is what they bolted on top of the repo to make it usable for people who do not want to learn git:
- A
newbutton on the web UI that scaffolds the files for you. The user never opens the file system. - A
claude.local.mdper user, not committed to the repo, that tells Claude their namespace and includes the line "don't go around and mess with other people's files." (Verbatim. That is the entire multi-user safety story.) - Slash commands that wrap the git ceremony.
/figmaruns a three-phase loop (extract from Figma, implement, verify in browser, repeat until match)./deploywalks through the GitHub CLI auth, refuses to push to main, creates a branch, opens the PR, monitors CI on a 30-second loop, and auto-fixes failures until checks pass. - Custom skills with scripts attached. They built
find-iconafter the team got tired of Claude hallucinating icon names; the skill iterates through 5,000 icon files instead of loading them into context.
Brian's foundational rule is the line I want you to take from this whole piece: "Anytime the AI asks you to do something, before responding, try your best to see if you could teach the AI to answer that question for itself." That move is what turns a junior-developer harness into a team-usable system.
Adoption reality matters, and Brian was honest about it. He is the most active user. About five to ten people at Notion use it regularly. A bunch of designers tried it and it did not stick. He shipped a feature to link to external prototypes (v0, Lovable, Figma Make) because not everyone wants to live in Next.js. The pattern works. Rollout, even at Notion, is uneven.
Which is why I treat the custom-app surface as almost always premature. Build it only when you have outgrown MCP and GitHub, and a non-technical UI is the actual unblock. If you have not yet validated the workflow with three to five documented runs, do not yet have the second brain in place, and your team is not yet using GitHub or MCP, you are reaching for the most expensive option because the cheaper ones felt "not professional enough." Most teams reach for this eighteen months too early.
Workflows can migrate up the stack, and most should start lighter than where they end up
The four surfaces above read like parallel options. They are not. In practice, most workflows start in the wrong home and migrate up the stack as the work hardens, and the migration is the part that is missing from almost every "where should we put this" conversation I have.
The sequence I see most often: a prompt and a couple of context notes start in Notion because that is where the rest of the team is already working. The output gets useful, then someone changes the prompt on a Tuesday and quality drifts on Wednesday. That is the moment the workflow earns GitHub (the diff is the whole reason). Cross-tool coordination becomes real, the agent now needs CRM context, then product docs, then campaign calendars in the same call, and that is the moment it earns MCP. Daily use plus a non-technical reviewer who has to participate is the moment it earns a custom app on top of the repo.
Each layer has to be earned by the workflow's actual behavior, not by how serious you want the system to feel. Most teams skip the migration entirely and pick the most expensive surface first because it sounds like the right answer. (It almost never is.)
Pick the surface by who runs the workflow on Tuesday morning, not how big the team is
The frame is one question per workflow: who needs to be able to run this on a Tuesday morning?

- A builder (engineer-comfortable, lives in a terminal): GitHub on its own. Optional thin app on top later.
- An operator (Claude Code user, not a coder, runs slash commands daily): MCP scales best; install is a one-time three-minute step and the surface afterward is identical to any other tool. GitHub with slash commands works too.
- A non-technical reviewer (no terminal, no git, browser tab only): MCP if you want them to consume your workflows. The full custom-app pattern (Brian's prototype-playground shape) only if they need to participate in creating new ones.
Treat the agent like a new employee. The skill file is the SOP you would hand a new hire. You do not bury new-hire SOPs inside a twelve-layer SharePoint folder, and you do not write them in PowerPoint. You write them in plain language and put them somewhere fast. The only difference is the "employee" is an agent, so optimize for what the agent reads well: flat markdown, fast location, clear instructions.
What to do Monday morning to put one workflow in its right home
If you are anywhere on the spectrum I described in the opening, here is the action list.
- Inventory every AI workflow you have shipped in the last 60 days. Group them by where each one actually runs (Claude Code, ChatGPT, Cursor, Codex, terminal). If you cannot list them in 30 minutes, the inventory itself is the work.
- Audit where each one's instructions live today. If the answer is "in my head" or "in a chat I cannot find," that is the gap. Write the instructions down in markdown before you decide on a surface.
- Pick the right surface. If you have at least one builder, start a GitHub repo this week. If you are a consultant or you want the team to consume without seeing source, build (or contract) the MCP server.
- Move one workflow. Pick a recurring one (the weekly ads report, a content repurposing flow, a lifecycle email pattern) and put it in the new home. Run it from there for two weeks.
- Add a change-review path. PR review in GitHub or an admin process for MCP updates. Decide who approves changes and how. This is the single missing piece in most teams' shadow AI, and it is the difference between a system and six drifting copies.
- Tell the team where to go. Most teams' workflows are stuck because the leader never explicitly said "this is where our AI workflows live now." Say it. In writing. Once.
Brian's rule, slightly adapted, is the closing thought: every time your AI asks you to do something, ask whether you could teach it to do that itself. That is what scales the system from one technical operator to a team. It is also what kills the "I'll just keep doing it myself" loop most leaders are stuck in right now. Shadow AI does not break because the team becomes more disciplined. It breaks because the leader picks a surface, says it out loud, and gives one Tuesday morning to migrating the first workflow.
Get curious. Then put the file somewhere your team can actually run it.
If you want to see what Surface 3 looks like in practice, MITL Pro is the working example: one MCP install, every skill I have built, three minutes to set up. If you are already a Pro member and you are stuck on rollout inside your team or your client, the free 30-minute support call exists for exactly this conversation. Questions? Respond to any MITL email– they go straight to me.
About Marketer in the Loop
Marketer in the Loop shows how an AI-native marketing practice gets built: what worked, what broke, and what you can use in your own system. It is published by MultiplAI Growth Partners, which helps agencies and marketing teams turn scattered AI experiments into working systems.
Build it yourself with MITL Pro
MITL Pro includes the MITL MCP, every current and future suite, downloadable templates, prompt packs, practical frameworks, the full Pro archive, and a 20-minute call with Hanna. Install one connector in Claude Code or another MCP-compatible client, then use the system from the tools you already work in.
Want a roadmap built around your business?
The Agentic Consult is a free, on-demand 8–10 minute conversation with an AI operating advisor. It asks what result you want, what you’ve tried, what worked, what didn’t, and what is blocking you. Hanna reviews the output, and your personalized roadmap arrives by email within an hour—with a clear diagnosis, three prioritized systems, an implementation sequence, and a measurement plan.
Free. No calendar booking required.